Mid Report
What have been finished
Up to now, everything go very well. We have designed the MPI version of the algorithm and implemented it. We have measured the speed up of the algorithm in one dataset. Now, we just use the library ublas in boost to do the matrix operation. In the coming weeks we will write our own matrix library to do some optimization with OpenMP and SIMD.
The design of MPI algorithm
Since the updating of each user and movie is independent, we can do the calculation in parallel in different nodes. Here the basic idea is that every node is responsible for updating a pre-allocated group of users and movies and after the updating, they will synchronize with each other to the the newest embdding data. Only the movies rated by the assigned users on a single node are stored in the memory for accessing. Here is the flowchart: 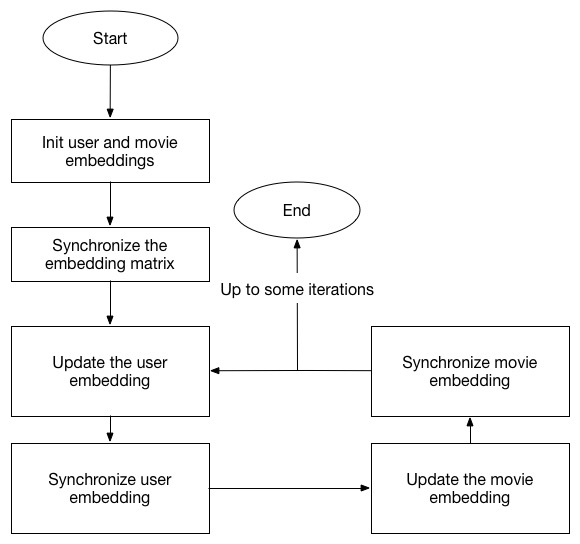
Now we assign each node with approximately equal number of number of movies and users, which may not lead to the optimal assignment of workload. Because different users usually rate different number of movies and it's also the same for the movies. We will evaluate the impact of this factor in the coming weeks.
Preliminary Results
We have done some experiments using the currently implemented naive MPI version. We measure the speedup on a single machine with multiple instances.
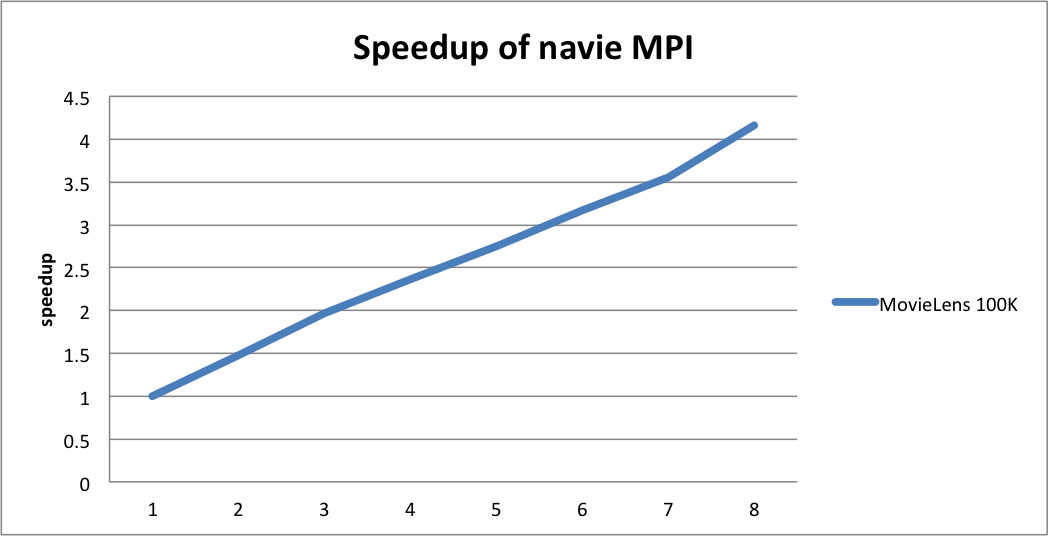 Here the machine tested on is installed with Intel(R) Xeon(R) CPU E5620 2.40GHz and we set the dimension of embedding matrix as 10 and run for 50 iterations. Here we can see that it scale up linearly but it doesn't reach the optimal.
Here the machine tested on is installed with Intel(R) Xeon(R) CPU E5620 2.40GHz and we set the dimension of embedding matrix as 10 and run for 50 iterations. Here we can see that it scale up linearly but it doesn't reach the optimal.
What need to be done and the challenge
After the implementation of the navie MPI version of the algorithm, we conclude the things need to be done and the challenge below:
- Matrix Library: Here we decide to implement a matrix library which is optimized for this project to replace the ublas library. We plan to implement with OpenMP and SIMD.
- Matrix Inverse Operation: Here the matrix needed to be inverted is positive-definite matrix, so we can do the inversion with conjugate gradient.
- Optimized with Xeon Phi [Extra]: For the extra part, we change it to the optimization by making using of Xeon Phi.
The final output will be some charts demonstrated the speedup we have achieved compared with the naive version.